Heute wollen wir uns ein bisschen mit dem WWW-Servern befassen. Man möchte doch wissen, wer greift auf den Server zu und welche Seiten sind von besonderem Interesse.
Nun jeder WWW-Server speichert alle Zugriffe und diese kann man auswerten. Ich nehme jetzt den Apache-Server als Beispiel heraus.Alle anderen speichern diese Daten ähnlich, selbst der MS-IIS.
Inhaltsverzeichnis
Und damit sollten wir ein paar Begriffe kennen.
Der Hit
Jedes Element das vom Server geladen wir, wird als Hit bezeichnet. Eine HTML-Seite ist ein HIT, ein Bild ist auch ein Hit und auch eine Javascript-Datei oder CSS-Datei wird als Hit gespeichert. Auch Hintergrund-Musik wird als Hit bewertet. Man kann ihn also mit einem URL gleichsetzen. Jeder Hit bedingt auch einen URL. Auch die Bilder einer Webseite sind wiederum Hits.
Die Page
Damit wird eine zusammengehörige Menge an Hits bezeichnet. Also das, was man so salopp gesagt lesen kann.
Der Request-Typ
Hier wird angegeben, wie dieser Request abgearbeitet werden soll. Die bekanntesten sind GET und POST. Daneben gibt es noch PUT, DELETE und HEAD und noch ein paar weitere. Wer diese genau wissen will, der muss den RFC lesen. Ich möchte an der Stelle nicht ins HTTP-Protokoll tiefer eingehen.
Der Referer
In diesem Feld wird der Quell-Url gespeichert. Also jene Adresse von der aus der Hit auffordert wurde. Das kann durchaus ein anderer sein.
Das response-code
Hier ist der Status, wie dieser Request abgehandelt wurde. wichtig sind die 2xx, 3xx, 4xx und 5xx Codes.
5xx Codes deuten auf einen Serverfehler hin (z.B. zu wenige Resourcen) . 4xx auf einen Handlingsfehler (Seite nicht gefunden, Anmeldug erforderlich). 2xx und 3xx sind Statusmeldungen.
Die Zeile in der Logdatei
Eine solche Zeile schaut jetzt folgendermaßen aus.
::1 – – [11/Jan/2026:18:17:08 +0100] „GET /cgi-bin/awstats.pl?databasebreak=hour&month=01&year=2026&config=localhost&framename=mainright HTTP/1.1“ 200 5689 „http://localhost/cgi-bin/awstats.pl?databasebreak=hour&month=01&year=2026&output=osdetail&config=localhost&framename=mainleft“ „Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/143.0.0.0 Safari/537.36“
Ihr findet die Beschreibung der einzelnen Felder und ihre Bedeutung unter diesem Link https://httpd.apache.org/docs/2.4/logs.html Ich möchte auf die Besonderheiten der Informationen eingehen und was man beim Auswerten beachten sollte.
Wer viel misst, misst viel Mist.
Die IP-Adresse „::1″
Die IP-Adresse oder der DNS-Name der hier gespeichert wird, ist die des letzten Absenders. Das muss nicht der Client sein. Es kann auch eine Firewall, ein Router oder ein NAT sein. Mit . getrennt deuten auf eine IPv4 Adresse. Ein : ist ein Zeichen für eine IPv6 Adresse. Dieses Feld wird gerne in den Auswertungen für „unterschiedliche Benutzer“ herangezogen. Bedenkt, dass es nur bedingt richtig sein kann. Ihr alle habt wahrscheinlich einen Router/Access Point zu Hause. Wenn Ihr über diesen Access-Point ins Internet geht, dann sieht der Server nur die IP-Adresse des Routers nicht aber die eigentliche des Endgerätes. Der Server kann damit nicht unterscheiden ob, ihr vom Handy oder vom PC surft. Dies gilt sinngemäß auch für SSL-Verbindungen. Allerdings in einem kleinerem Umfeld.
der User
Diese nächsten 2 Felder sind für die Identifizierung des Benutzers vorgesehen. Wobei das Feld 3 für die HTML-Identifizierung genutzt wird. Wir kommen später noch auf das Feld bei der „Anmeldung“ zu sprechen.
der Request URL „GET /cgi-bin „
im URL Feld findest ihr neben den Typ auch den eigentlichem Url „/cgi-bin/awstats.pl“ dann ein ? und diverse Begriff-Wert Paare getrennt durch ein &. Den Abschluss macht die Version des HTTP-Protokolls. In meinem Fall 1.1. Möglich wären noch 1,0 und 2.0. Der URL /cgi-bin sagt nichts über den wirklichen Platz auf der Platte aus. Wer ein Verzeichnis /cgi-bin bei mir sucht, wird enttäuscht sein. Es ist ein Konfigurationsparameter des Apache. Ich könnte jetzt eine zweite Seite nennen wir sie index.html auf den gleichen Path legen. und den Apache anweisen index.html meldest du mit /cgi-bin/index.html.
In meinem Fall wird ein Programm aufgerufen das Programm awstats.pl. Awstats.pl ist ein Web-Logdateien Auswertungsprogramm; in Perl geschrieben. Das Programm soll den Jänner 2026 auswerten.
Der Response Code
sagt aus wie der Request abgearbeitet wurde. 200 ist der OK Status. 303 wäre nicht verändert oder 404 Datei nicht gefunden. Die 5xx wäre ein Server-Problem. Auch diese sind im RFC beschrieben.
der User-Agent
dieses Feld ist vorgesehen um Browser spezifische Unterscheidungen, durch zuführen. Zu Beginn des WWW haben sich die Firmen Netscape und Microsoft eine Schlacht um die Marktanteile geliefert. Irgendwann gab Netscape auf und machte ein Open-Source-Projekt daraus. Heute findet man den Netscape-Nachfolger und die gebräuchlichsten Browser . Ggf sind hier auch Informationen über das Betriebssystem gespeichert. In meinem Bespiel X11 und Linux auf 64Bit x86 😉
der Benutzer
Diese Informationen stehen uns zur Verfügung. Zusätzlich, KANN uns noch ein User(name) mitgespeichert werden. Defaultmäßig wird nur der HTTP-User im Log gespeichert. Loginverfahren die über Cookies, Request-ID oder ähnlichem arbeiten, werden nicht protokolliert. Weil somit nur die IP-Adresse als Unterscheidungsmerkmal zur Verfügung steht, sind die Werte über die Benutzeranzahl mit Vorsicht zu behandeln.
So wird das Log aufgebaut und diese Daten sind gespeichert. Nun geht es an das Auswerten.
Das Log-File
Bei den beiden wichtigsten Servern Apache und NGINX wird eine Textdatei angelegt. Wir bleiben bei Apache und Debian und finden unser Log unter /var/log/apache/access.log. Dort wird es standardmäßig angelegt und in regelmäßigen Abständen getauscht und gezipped.
Die Anmeldung
Es gibt mehrere Möglichkeiten, wie ich einen User identifizieren kann. Die Einfachste ist über eine „passwd“- Datei und eine Rule in der Apache-Config, dass ein bestimmter Bereich nur von einer Gruppe oder einzelnen User gelesen werden darf. Dabei wird bei jedem Request der User und das Passwort gesendet. Das Ganze wird noch mit dem alten Befehl md5 Verfahren gesichert. Einfach und schnell aber knackbar in Sekunden.
Ein bisschen besser wird es wenn man auf „digit“ umstellt.
Aber wenn ich diesen Teil des Frame habe, kann ich ihn von einem anderem Gerät senden und bin angemeldet. Bei diesem Verfahren ändern sich die Werte nur wenn sich das Passwort ändert, also nie.
Dazu kommt, das große Sites, die über viele Server gehen, immer den gesamten Uservorrat speichern müssen.
Also hat man sich eine andere Anmeldeform überlegt. Und da kamen cookies und SessionID ins Spiel, ein Server erzeugt aus User und Passwort eine Prüfsumme den Token oder SessionID und sendet diese an den Client. Bei jedem weiteren Request wird dieser Wert mitgesendet und der/die Server können, es abprüfen und entsprechend reagieren. Cookies haben den Nachteil, dass sie nur auf eine bestimmte Gruppe von Servern funktionen (Domain-Cookie).
Wenn man Kerberos mit der Lösung dieses Problems vertraut, dann kommt die SessionID zum Tragen. Bei der Anmeldung wird ein Token erstellt, der als SessionID gespeichert wird. Diese ID kann auch an andere Server weitergegeben werden und wird gegengecheckt. Nachteil: Ich brauche eine vernünftige Infrastruktur. Sicherungsmechanismen wie „Salt and Pepper“ sind implementierbar und auch Zertifikate kann ich verwenden.
Was ich noch kurz mitteilen möchte ist, dass diese Daten im verschlüsseltem HTML-Teil übertragen werden, Also bei HTTPS nicht einsehbar sind.
WWW-Auswertungsprogramme
Das Auswertungsprogramm AWSTAT
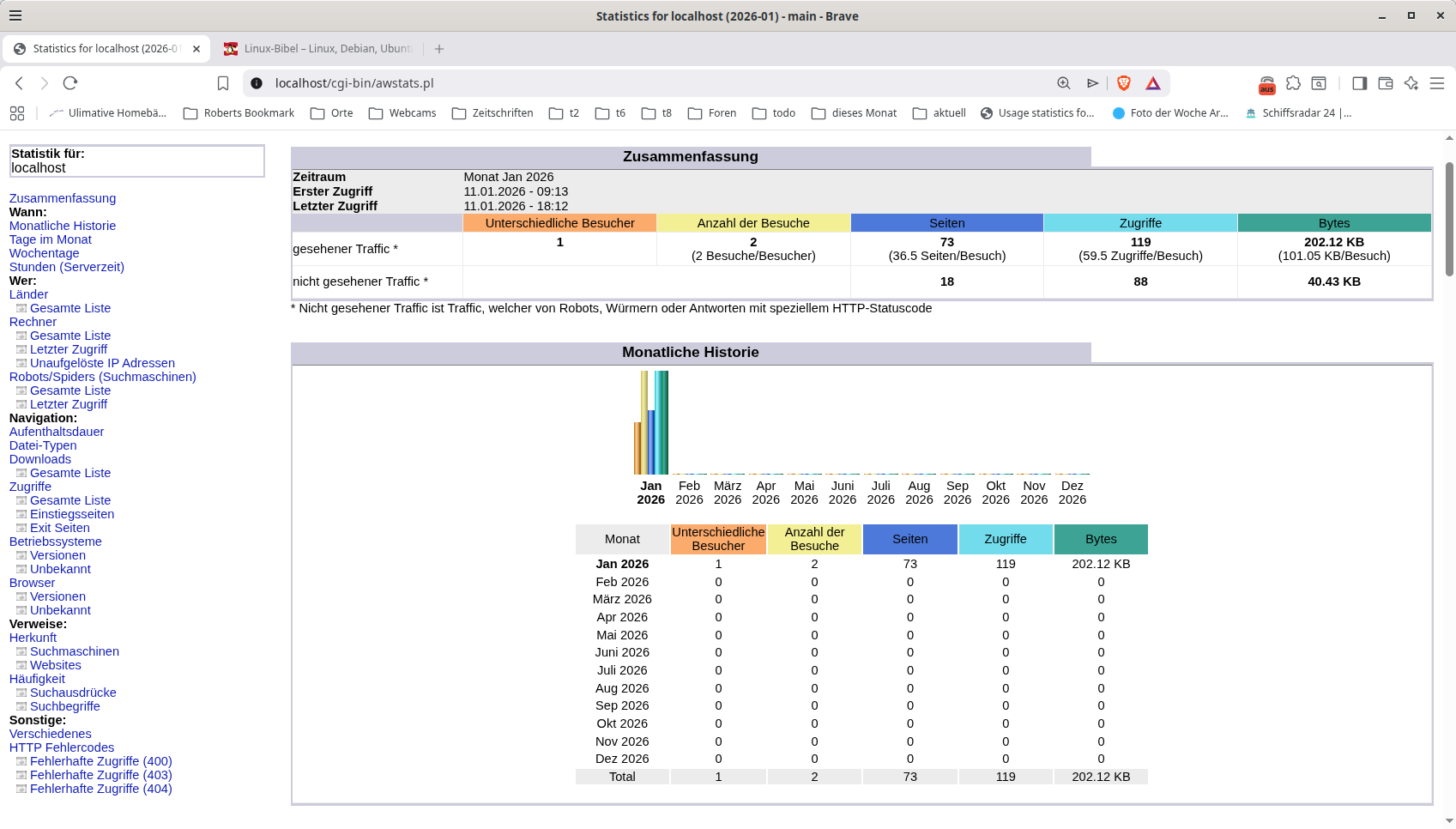
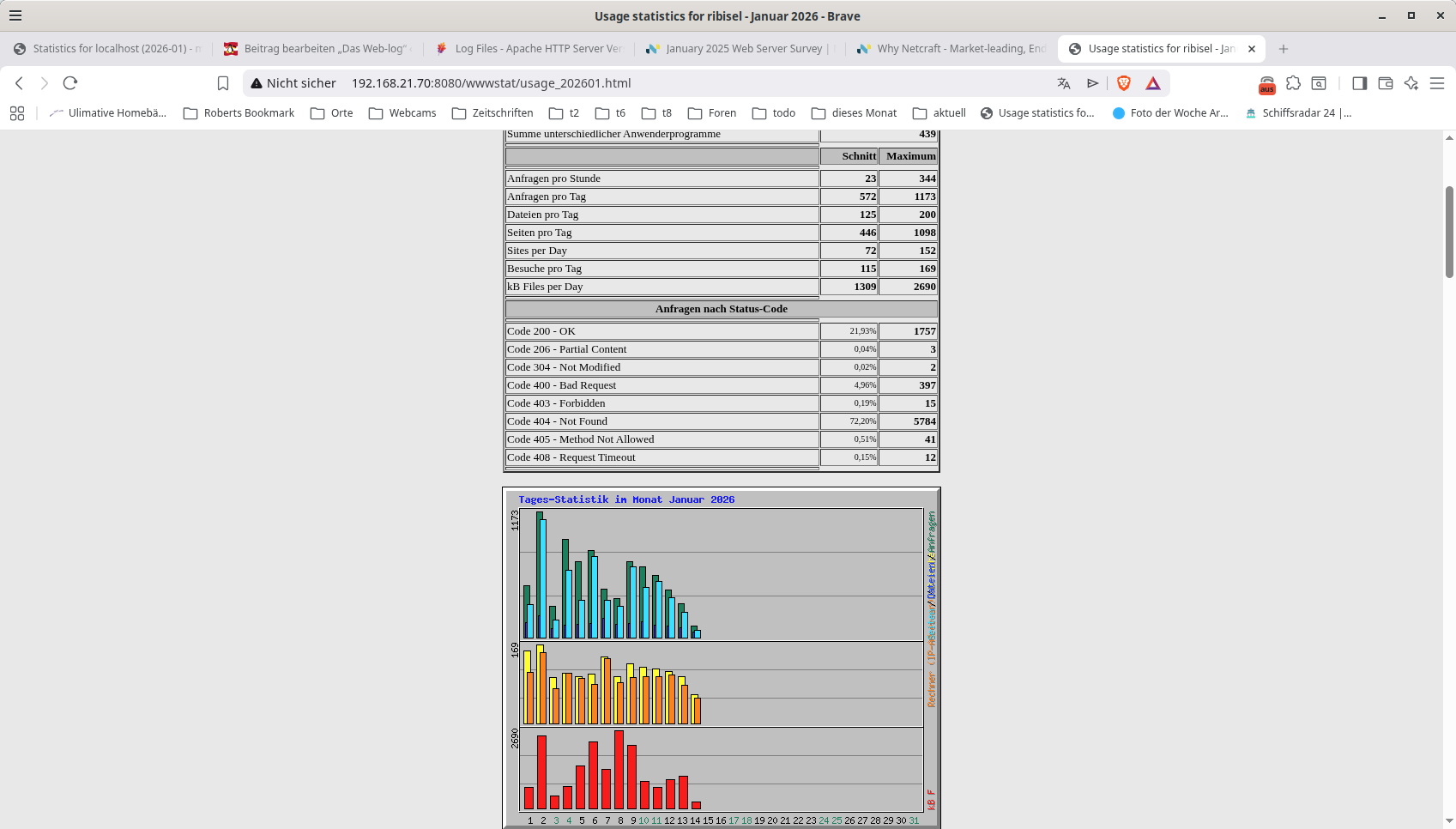
Die Auswertung umfasst neben Tage, Monate, Besuche, Einstiegseiten, Ipadressen und Ausstiegsseiten auch Pages und Hits. Besonders die Auswertung auf Fehlercodes bringt so einiges an Versuchen von bösen Jungs zum Vorschein.
Das 2. Programm, dass ich euch vorstellen möchte heißt
Das Programm webalizer
und ist ein C-Programm. Es liegt in lauffähiger Form und im C-Code vor und kann von Heise geladen werden. https://www.heise.de/download/product/webalizer-2038 . Das Programm wird nicht mehr weiterentwickelt. Es gibt allerdings 2 Nachfolge-Projekte, die auch im Stocken sind. Der Leistungsumfang ist ähnlich.
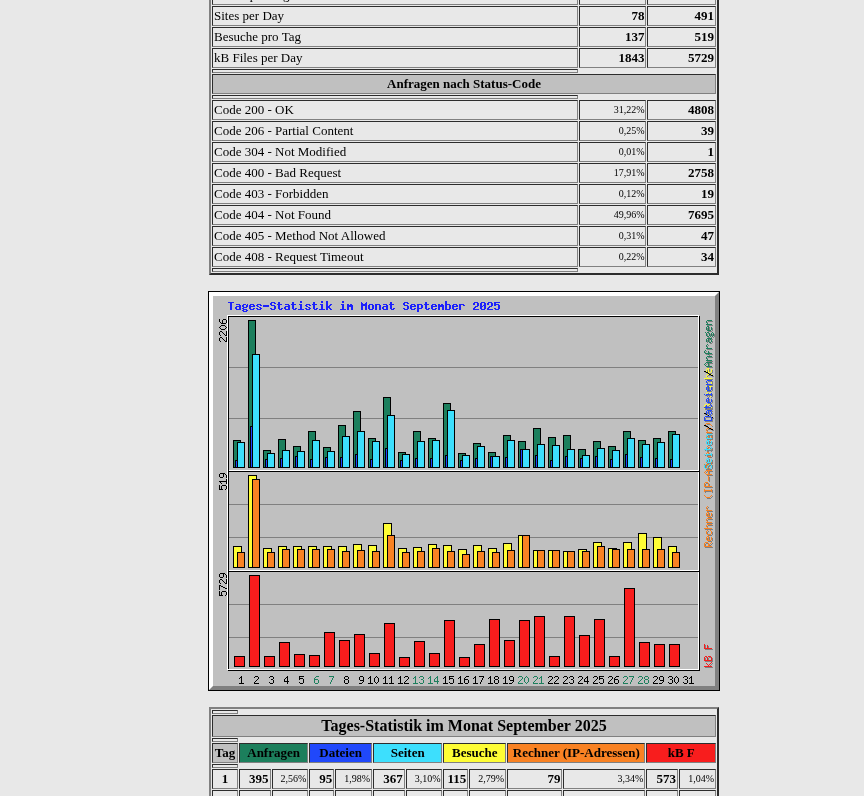
Trotzdem sind beide Programme noch benutzbar und liefern wichtige Informationen über die Nutzung eures Servers.
Webalizer wird entpackt und liegt dann kompiliert vor. Es empfiehlt sich, vor dem ersten Start nochmals in die Config-Datei zu schauen. Und die Verzeichnisse bzw den Leistungsumfang anzupassen.
 3
3

Noch keine Reaktion