Vieles gelingt am Terminal um vieles schneller als auf der grafischen Oberfläche – dies ist unter Linux wie unter Windows so, wenn man nur versteht wie es funktioniert. Um Textdateien aller Art (txt, html, c, php, perl, …) zu durchsuchen, nutzt man unter Linux meist den Befehl:
grepZunächst sehen wir uns an, wie man grep nutzt, zuletzt werden wir uns mit regulären Ausdrücken befassen – solche dienen bei der Suche nach nicht genau definierten Zeichenfolgen.
In allen Beispielen nehmen wir an, wir befinden uns bereits im Verzeichnis mit allen Textdateien, wir brauchen also keinen Pfad zu diesen anzugeben.
Nun nehmen wir einmal an ich habe hier eine Datei mit der Bezeichnung „Textdatei.txt„, ich möchte diese nach dem Begriff „Durchgang“ durchsuchen, die Syntax des Befehls würde ganz einfach so lauten:
grep Begriff DateinameIn diesem Beispiel würde der Befehl also so aussehen:
grep Durchgang Textdatei.txt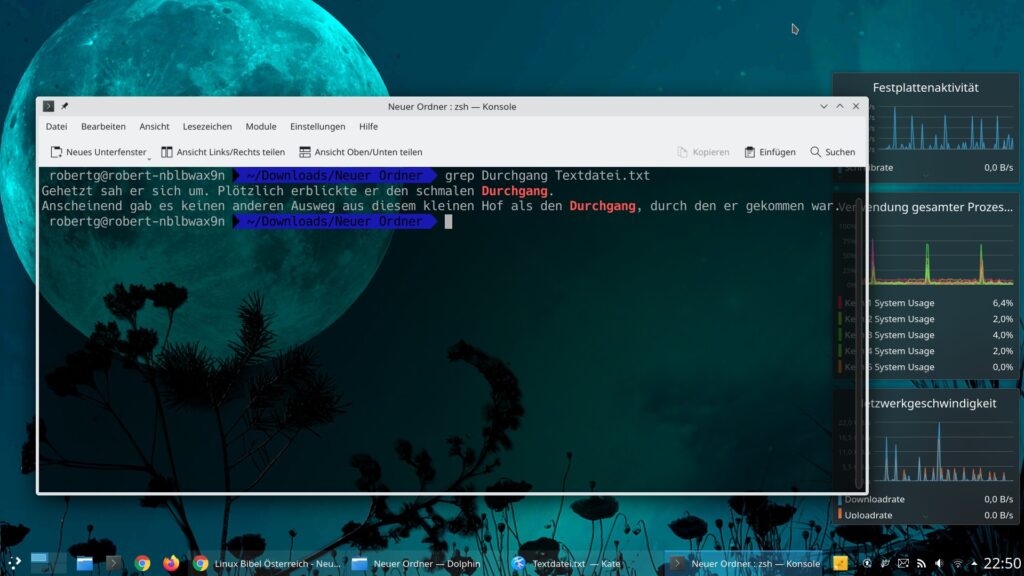
Die Software zeigt die Zeilen, in denen der Begriff vorkommt an und markiert den Begriff. Sich alleine die Zeilen anzuzeigen hilft in vielen Fällen nicht sonderlich viel, wenn man in der Textdatei später die Zeilen erst wieder suchen muss – mit der Option „-n“ zeigt die Software zusätzlich die Zeilennummer an, in der der Begriff zu finden ist:
grep -n Durchgang Textdatei.txt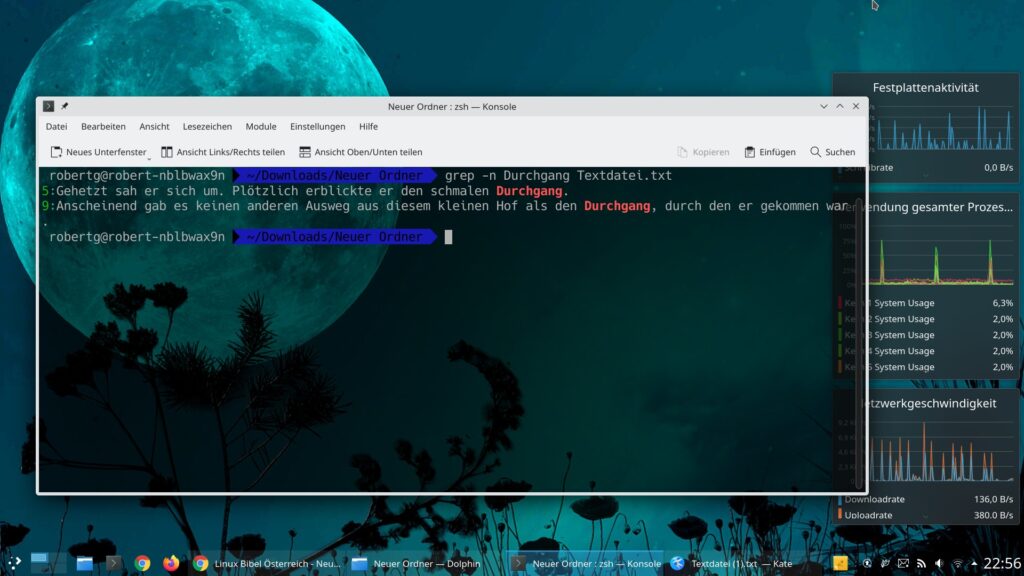
Grundsätzlich durchsucht die Software wie unter Linux üblich genau nach dem angegebenen Begriff – es wird also Groß- und Kleinschreibung unterschieden:
grep Durchgang Textdatei.txtwürde als den Begriff „Durchgang“ suchen, aber nicht „durchgang„. Möchte man sich beide Varianten anzeigen lassen, also Groß- und Kleinschreibung nicht beachten, nutzt man zusätzlich die Option „-i„:
grep -i Durchgang Textdatei.txt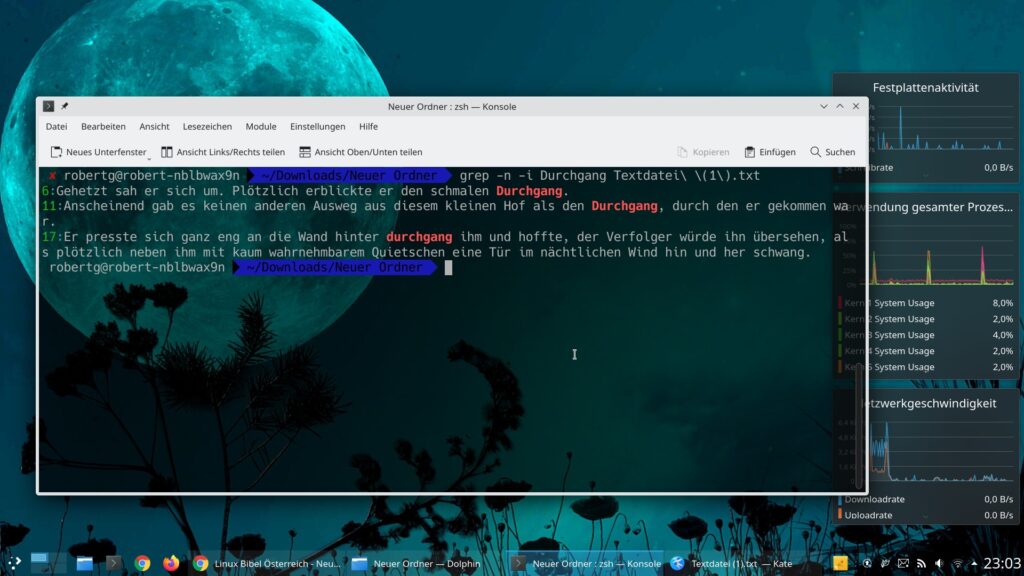
Handelt es sich nicht nur um ein Wort, sondern um mehrere durch Leerzeichen getrennte, setzt man diese unter Anführungszeichen – etwa:
grep "kleinen Hof als den Durchgang" Textdatei.txt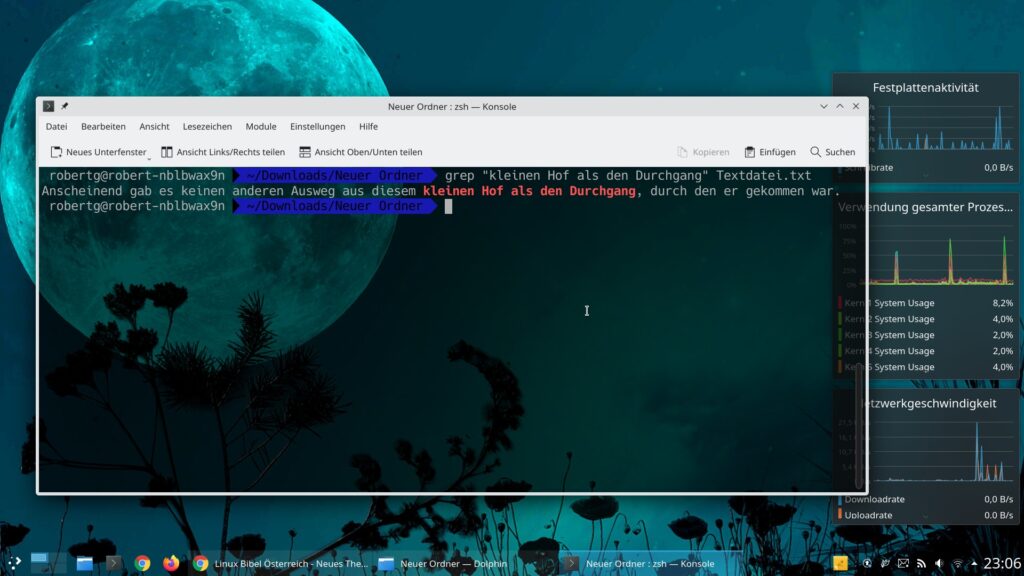
Nun lassen sich natürlich auch alle Dateien eines bestimmten Dateiformates anzeigen, im Beispiel einfach alle Dateien mit der Endung „.txt“ – man nutzt statt des Dateinamens einfach den Platzhalter „*„:
grep -in Durchgang *.txt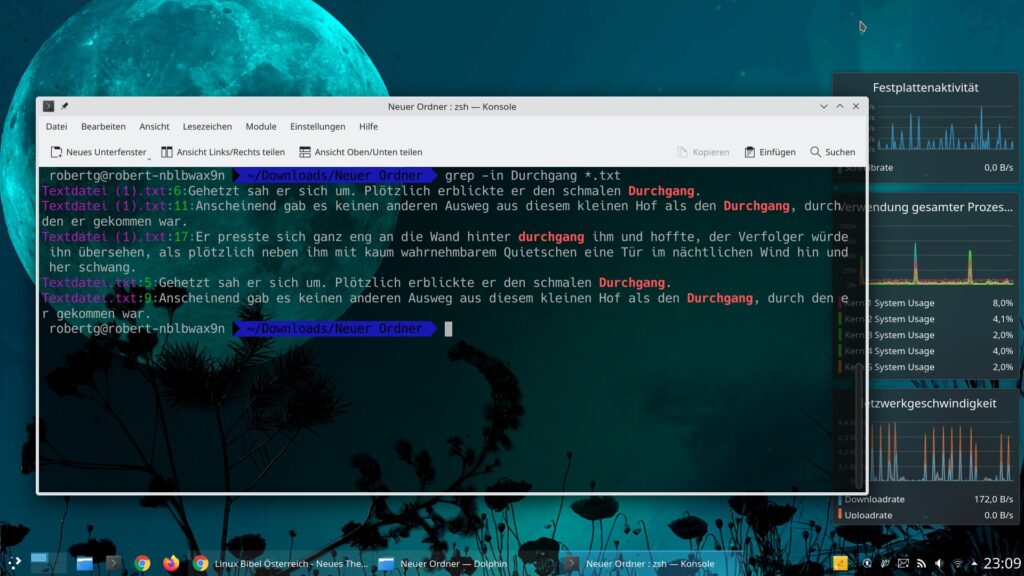
Alternativ geben Sie einfach gar keine Dateiendung an, um alle Textdateien aller Formate zu durchsuchen:
grep -in Durchgang *Nutzen Sie zusätzlich die Option „-r“ werden auch Unterverzeichnisse rekursiv durchsucht – geben Sie jedoch keine Dateiendung an (ansonsten werden Unterverzeichnisse nicht durchsucht):
grep -rni Durchgang *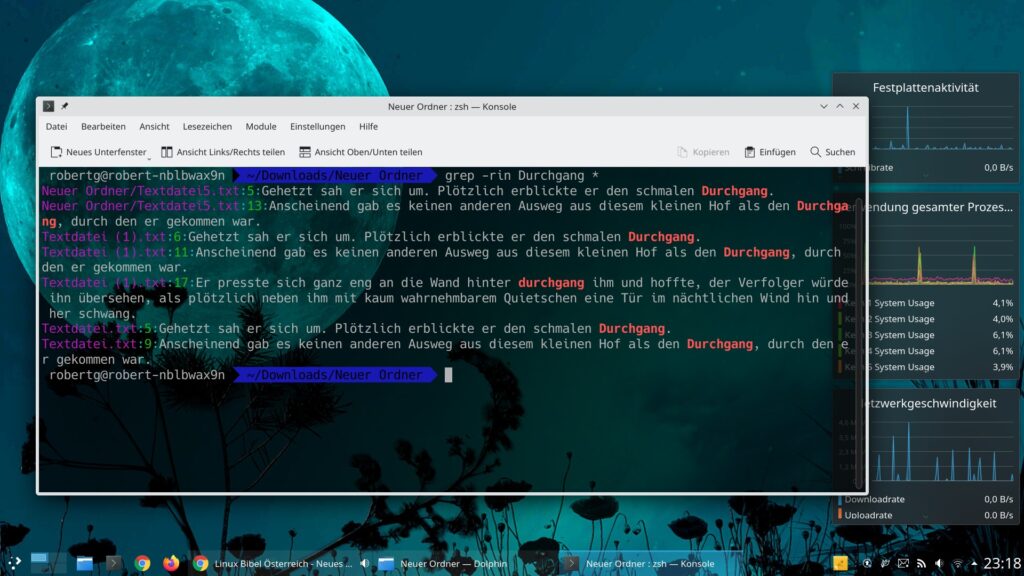
Liegen Dateien in Unterverzeichnissen wird der Pfad zu diesen entsprechend angezeigt. Je nach Anzahl von vorhandenen Dateien könnte die Ausgabe natürlich länger sein, in solchen Fällen ist es interessanter die Ausgabe an den Reader less zu übergeben:
grep -rni Durchgang * | lessIn diesem lässt es sich anschließend mit den Pfeiltasten und der Leertaste scrollen – beendet wird less wie üblich mit der Taste q.
Reguläre Ausdrücke (regular expressions)
Reguläre Ausdrücke dienen dazu, auch Begriffe zu finden, die man nicht so genau definieren kann. So erlauben es reguläre Ausdrücke etwa unterschiedlich geschriebene Wörter zu suchen, etwa die Wörter „Saat“ und „Maat“ ohne beide Wörter angeben zu müssen. Sehen wir uns einmal einige reguläre Ausdrücke an – reguläre Ausdrücke werden meist unter eine eckige Klammer gesetzt:
- abcd – Findet genau diese Zeichenfolge
- [abcd] – Alle unter Klammer gesetzten Zeichen werden gefunden, so würde „[Hh]ahn“ unter anderem „Hahn“ als auch „hahn“ finden. Ein Beispiel:
grep -rni "[Hh]ahn" *- [a-d] – Findet alle Zeichen aus dem angegebenen Bereich, so würde also etwa „[A-K]ahn“ unter anderem „Hahn“ als auch „Kahn“ finden.
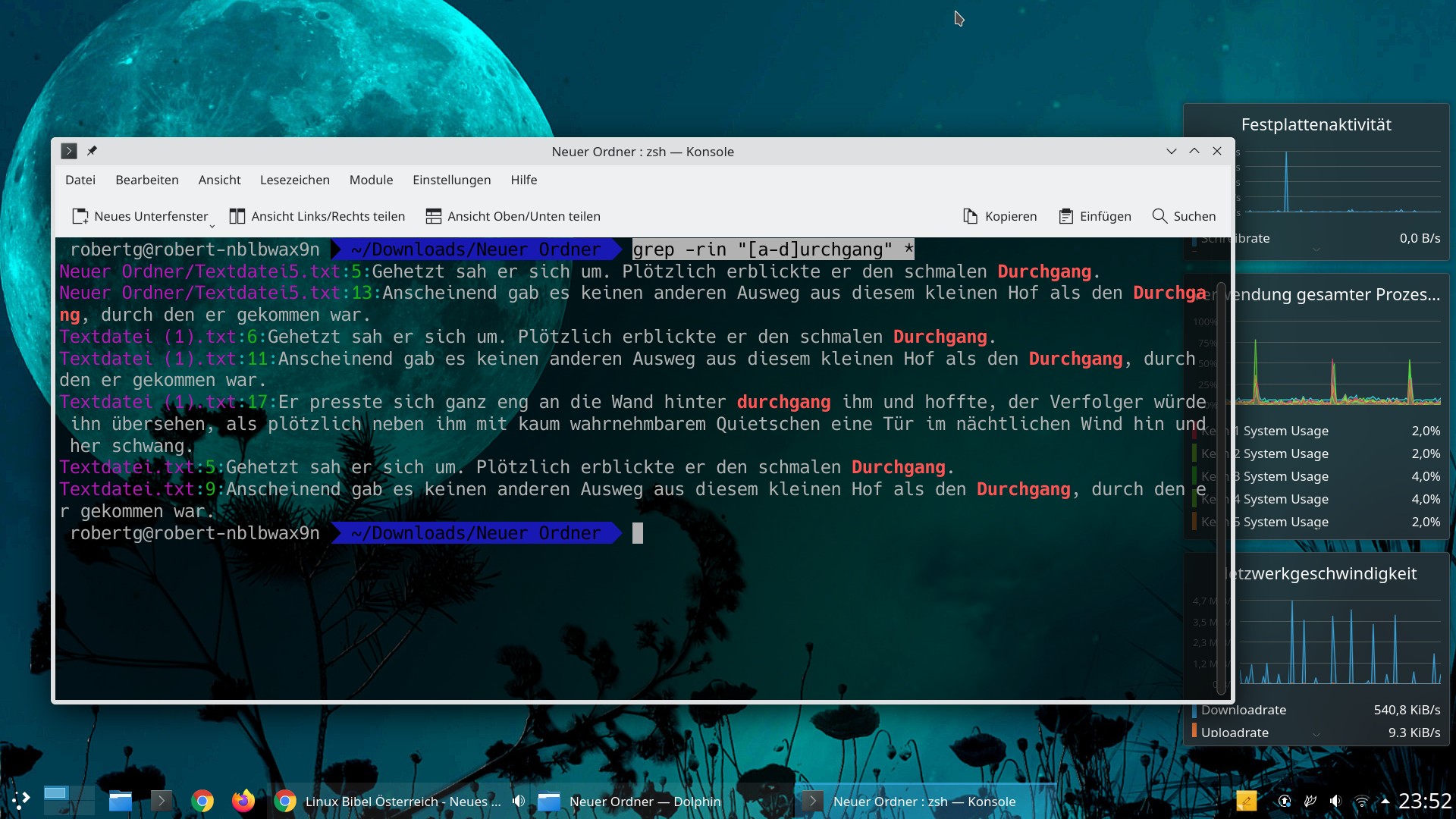
grep -rin "[a-d]urchgang" *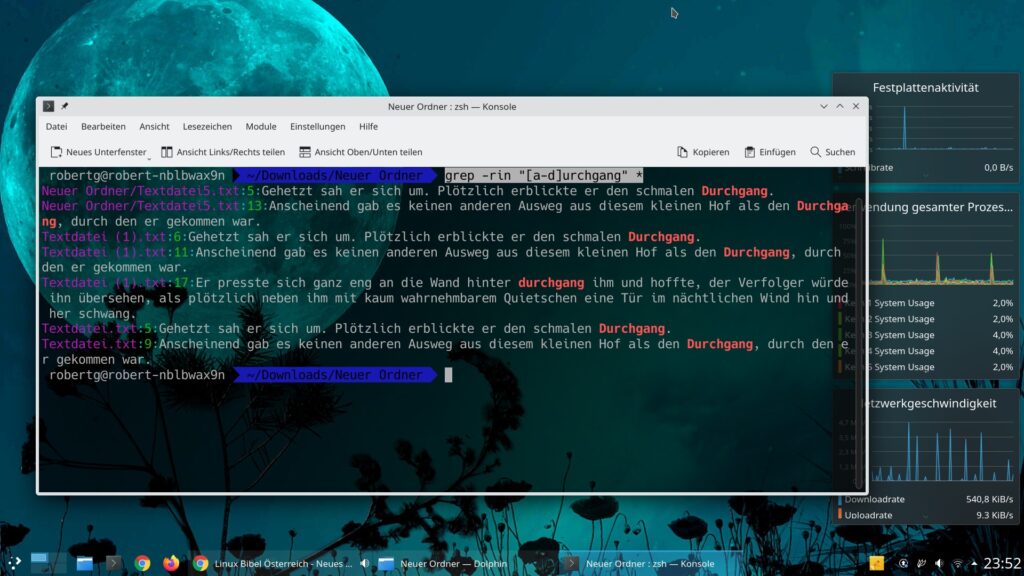
- [^abcd] – Keines der angegebenen Zeichen darf vorkommen, so würde „[^A-H]ahn“ das Wort „Kahn“ finden, jedoch nicht „Hahn„
- . – Ersetzt ein beliebiges Zeichen, so würde „H.hn“ das Wort „Hahn“ als auch das Wort „Huhn“ finden
- ? – Das Zeichen vor dem Fragezeichen kann einmal oder auch gar nicht vorkommen, so würde „w?einen“ das Wort „Weinen“ als auch „einen“ finden
- * – Das Zeichen vor dem Sternchen darf beliebig oft oder auch gar nicht vorkommen, so würde „Gas*e“ das Wort „Gasse“ wie auch „Gase“ finden
- .* – Steht für eine beliebige Anzahl beliebiger Zeichen oder auch kein Zeichen, so würde „.*Huhn“ das Wort „Huhn“ als auch „Suppenhuhn“ wie auch „Suppen-Huhn“ finden
- + – Das Zeichen vor dem Plus muss mindestens einmal vorkommen, aber auch beliebig oft, so würde „Bo+t“ das Wort „Bot“ wie auch „Boot“ oder eben auch (wenn auch unsinnig) „Boooot“ finden
- ^Begriff – Findet den gesuchten Begriff, wenn dieser am Beginn der Zeile steht
- Begriff$ – Findet den gesuchten Begriff, wenn dieser am Ende der Zeile steht
Eine vollständige Dokumentation zu regulären Ausdrücken erhalten Sie mit der Manpage mit dem Befehl:
man 7 regexPDF-Dateien durchsuchen
Für PDF-Dateien können Sie die Software Pdfgrep nutzen, diese installieren Sie über unter auf Debian basierenden Linux-Distributionen über die Paket-Verwaltung durch das Paket „pdfgrep“, genutzt wird diese wie der Befehl grep – hier nutzen Sie natürlich den Befehl:
pdfgrepAuch reguläre Ausdrücke funktionieren natürlich.
Eine Reaktion
[…] 2) Bei „Suchmuster“ kann man ein einzelnes Wort oder einen zusammenhängenden Teil eines Textes eintragen. Darunter hat man wiederum die Möglichkeit, verschiedene Haken zu setzen. Zu „RegExpr“ siehe den Abschnitt „Reguläre Ausdrücke (regular expressions)“ im Linux-Bibel-Beitrag „Textdateien mit grep und regulären Ausdrücken durchsuchen“. […]