
Vom eigenen Gesprochenen eine Audio-Aufnahme zu erstellen, ist unter Linux das Einfachste. Hin und wieder braucht man diese Aufnahme auch als geschriebenen Text. Für diesen Fall braucht man schon etwas anderes an Software – unter Linux ist aktuell dafür die beste Software Whisper.
Sie sprechen nur noch den Text ins Mikrofon, und die Software schreibt Ihre Worte in eine Textdatei.
Inhaltsverzeichnis
Whisper installieren
Unter auf Debian basierenden Linux-Distributionen installieren Sie über die Paket-Verwaltung die Pakete „build-essential ffmpeg git„, etwa gleich als root am Terminal mit dem Befehl:
apt install build-essential ffmpeg gitAnschließend laden Sie die eigentliche Software mit normalen Benutzerrechten herunter:
git clone https://github.com/ggerganov/whisper.cpp.gitJetzt wechseln Sie in das heruntergeladene Verzeichnis:
cd whisper.cppBisher haben Sie nur die eigentliche Software heruntergeladen, dazu gehört noch das Übersetzungsmodell. Dieses gibt es in vier verschiedenen Varianten und wurde von ChatGPT entwickelt. Die Modelle unterscheiden sich in Dateigröße und benötigtem RAM. Je größer die Datei, desto mehr RAM benötigt das Modell. Und je größer die Datei, desto besser ist aber auch die Erkennung.
Die Modelle nennen sich tiny (80 MB, benötigt rund 130 MB RAM), base, small, medium und large (2,9 GB, benötigt rund 3,3 GB RAM). large hat natürlich die beste Erkennung. Jetzt gilt es, die Software mit dem gewünschten Modell zu kompilieren – hierzu nutzen Sie den Befehl make mit dem gewünschten Modell, also etwa (als normaler Benutzer):
make tiny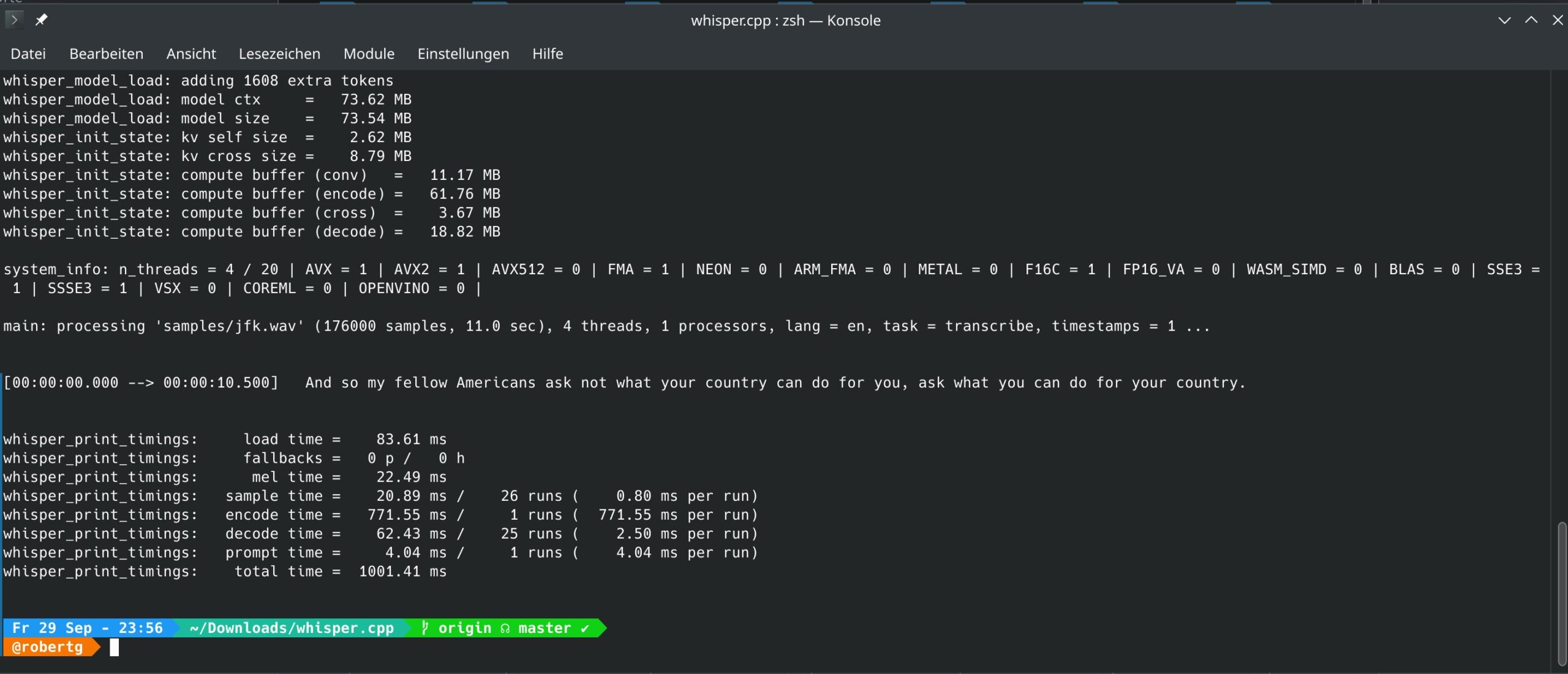
Das angegebene Modell wird dabei automatisch aus dem Netz geladen und die Software kompiliert. Anschließend verschieben Sie das komplette Verzeichnis als root auf dem Terminal nach /opt:
cd ..
mv whisper.cpp/ whisper
mv whisper/ /opt/Damit Sie nicht für jeden Start der Software zweimal den langen Pfad über /opt angeben müssen, erstellen Sie noch einen Symlink von main auf whisper (ebenfalls als root):
cd /usr/local/bin/
ln -s /opt/whisper/main whisperWhisper nutzen
Sie starten die Software auf dem Terminal, nach dem Start braucht die Software etwa 15 Sekunden und ist bereit. Mit -t geben Sie die zu nutzenden CPU-Kerne an, mit -m das Modell – dieses liegt unter /opt/whisper/models/ und beginnt mit „ggml-modell.bin„, in meinem Beispiel also „ggml-tiny.bin„. Mit -l geben Sie die Sprache an, etwa de, es folgt die Option -otxt und mit -of geben Sie die zu erstellende Textdatei an – etwa Textdatei.txt. Zum Schluss folgt die zu erstellende Audio-Datei – im Beispiel ganz einfach Audio.wav, Beispiel:
whisper -t 4 -m /opt/whisper/models/ggml-tiny.bin -l de -otxt -of Textdatei.txt Audio.wavDie Software nimmt Ihren gesprochenen Text in die Datei Audio.wav auf, schreibt den erkannten Text in die Datei Textdatei.txt. Sobald die Software fertig ist, beendet sich diese selbst. Dies dauert natürlich etwas, funktioniert jedoch schon prächtig.
 3
3
 1
1
2 Reaktionen
Das Programm Whisper für Speach to text (STT) installieren und nützen
Bei mir ging es so:
Installieren
1 ffmpeg muss installiert sein.
2 Python muss installiert sein.
3 Im Terminal:
sudo apt install pipx4 Im Terminal:
pipx install git+https://github.com/openai/whisper.gitNützen
5 Eine Audio-Datei.mp3 mit gesprochenem (evtl. gesungenem) Text „nehmen“ (oder produzieren).
6 Im Terminal: Mit
cdins Verzeichnis wechseln, in dem sich die Audio-Datei befindet.7 Im Terminal:
whisper Audio-Datei.mp3 --model medium --language German8 Warten und im Terminal verfolgen, was geschieht.
9 Am Ende (wenn wieder der Prompt erscheint) befinden sich in diesem Verzeichnis neu 5 Dateien – mit den Endungen .txt, .vtt, .tsv, .srt, .json
In der TXT-Datei ist der Text ohne zusätzliche Zeichen enthalten.
Zum Nützen
Am besten ist:
--model large(2 kurze Striche vor model)Statt German gibt es auch andere Sprachen, je nachdem, siehe (im Terminal:)
whisper --help(2 kurze Striche)So hat es super gut funktioniert, whisper läuft!
Mit der Anleitung unter https://linuxhint.com/install-pytorch-nvidia-gpu-cuda-acceleration-support-debian-12/ habe ich nun die Grafikkarte zum Mitarbeiten gekriegt und will nun ausprobieren, wie beides zusammenspielt.