Vor einigen Zeiten war man schon glücklich, wenn man Dokumente einfach nur einscannen konnte – heute geht man noch etwas weiter. Man packt Papier nicht nur in digitaler Form auf die Festplatte (natürlich auch auf die SSD – ist für mich dasselbe, weil ich es einfach nicht immer erwähnen will), man macht diese Dokumente auch durchsuchbar – eben nach dem Text, der in diesen Dokumenten vorhanden ist.
Damit man Dateien nach beinhaltetem Text durchsuchen kann, darf man das Papier nicht einfach nur einscannen und als Bild speichern – man muss zusätzlich eine Software nutzen, die den Text auch in diesen Bildern erkennt und in digitaler Form speichert. Optimal für solche Aufgaben ist natürlich das PDF-Format.
Software, die Text auf Bildern erkennt, nennt man in einem Begriff schnell gesagt eine solche, die OCR – Optische Texterkennung – beherrscht. Unter Linux ist dafür meist Tesseract zuständig. Grafische Oberflächen dafür gibt es unter Linux dafür auch so einige – genannt wurde auf der Linux Bibel bereits die äußerst umfangreiche Software Paperwork. Braucht man nicht alle Funktionen, nutzt man etwa Gscan2pdf – und um diese Software geht es in diesem Beitrag der Linux Bibel.
Inhaltsverzeichnis
Gscan2pdf installieren
Unter auf Debian basierenden Linux-Distributionen installiert man diese Software wie üblich ganz einfach über die Paket-Verwaltung mit den Paketen „gscan2pdf tesseract-ocr-deu„.
Gscan2pdf nutzen
Sie finden diese Software nach der Installation im Anwendungsmenü unter der Kategorie Grafik, alternativ nutzen Sie den Schnellstarter (Alt+F2) oder das Terminal mit dem Befehl:
gscan2pdf
Jetzt nutzt man ganz einfach das Menü „Datei → Scannen“ oder den Schalter „Dokument scannen“ in der Werkzeugleiste:
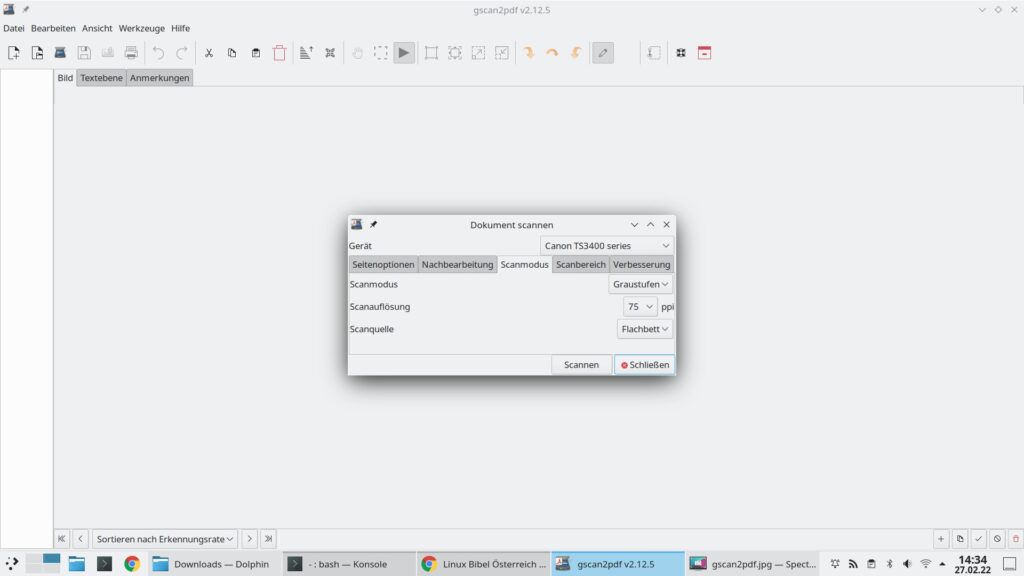
Und startet den Scan-Vorgang. Ist der Vorgang abgeschlossen, schließt man das Fenster zum Scannen:
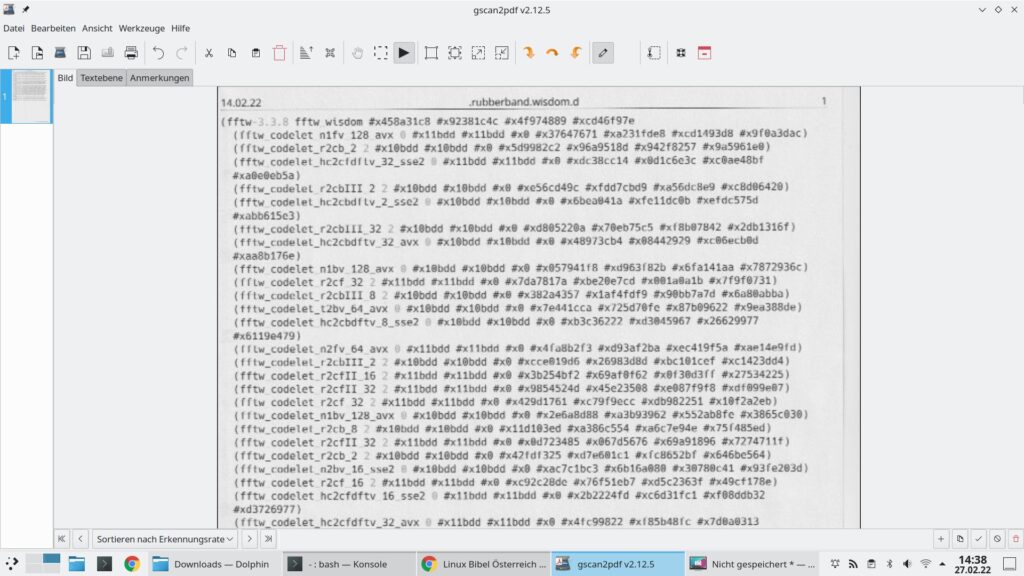
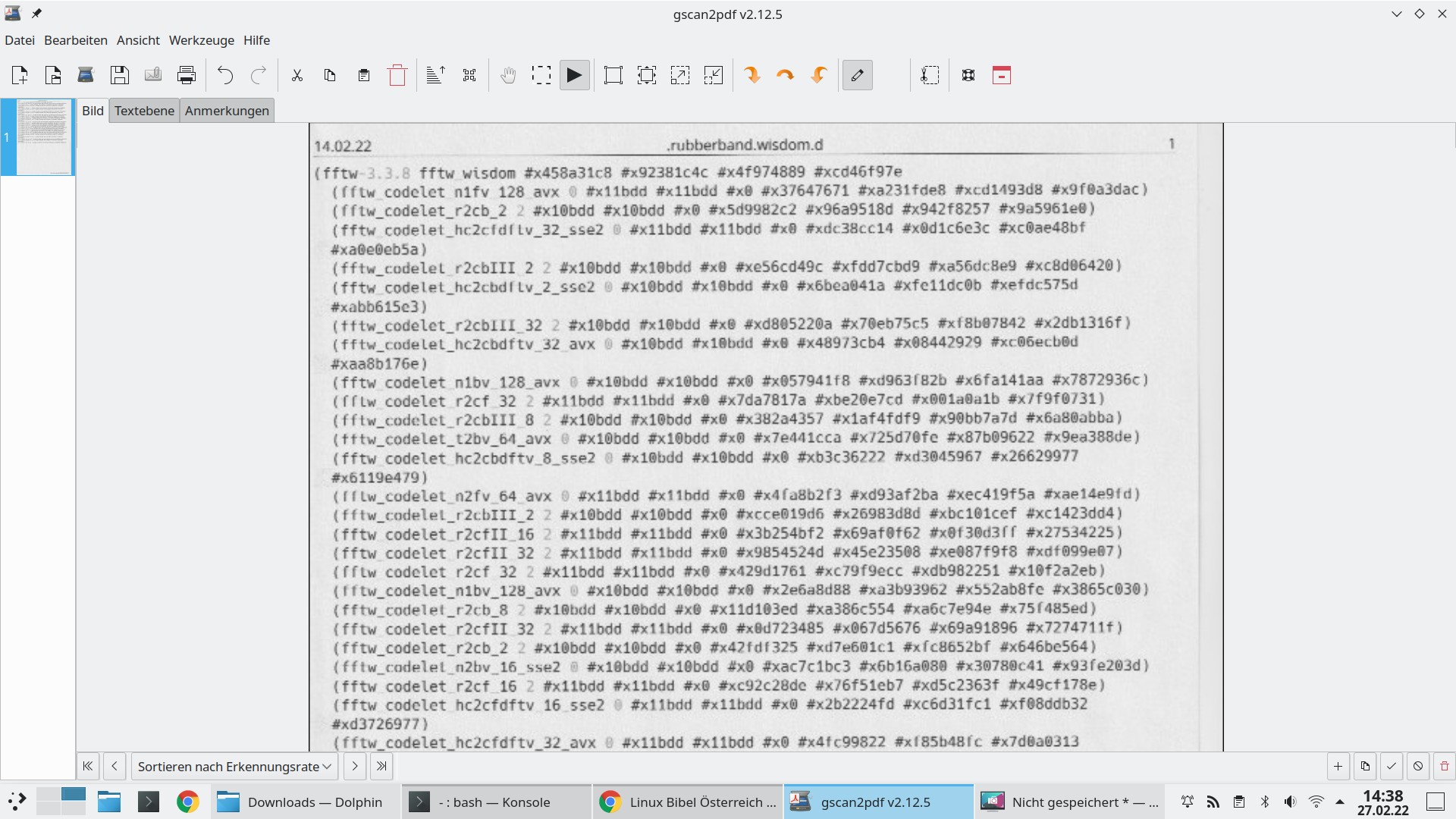
Ich habe hier das erste erwischt, was ich gerade gefunden habe – ein Testausdruck einer Konfigurationsdatei – man darf also nicht wirklich etwas Deutsches erwarten. Per Rechtsklick lässt sich die drehen und anderweitig anpassen, gewünschte Stellen für die Texterkennung markieren – im besten Fall klicken Sie einfach auf den Reiter „Textebene„:
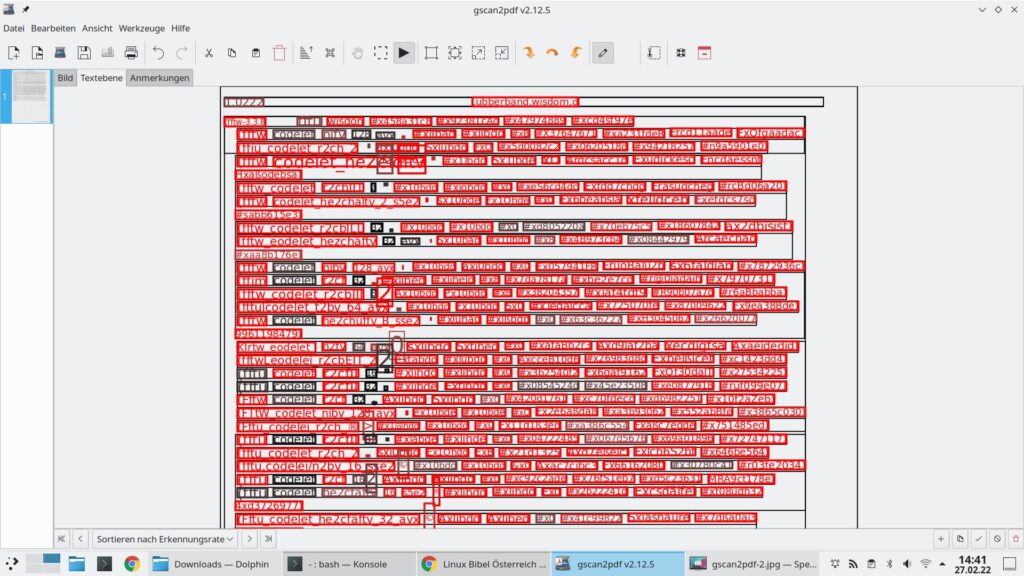
Nicht perfekt erkannte Wörter, oder solche, die nicht der deutschen Sprache zuzurechnen sind, markiert die Software rot. Ein Klick auf einen solchen Eintrag vergrößert diesen:
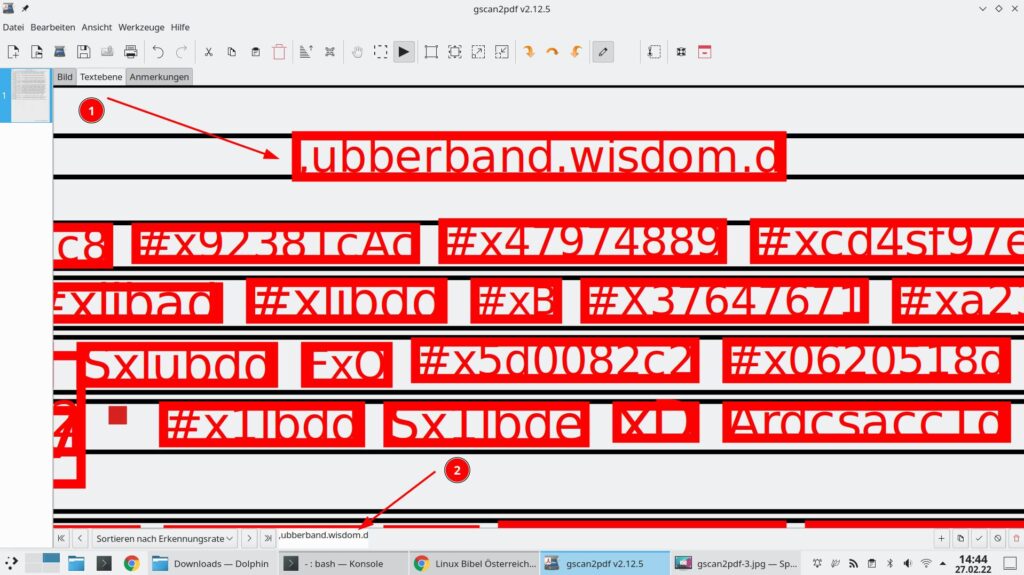
Der Markierte Eintrag lässt sich nun unten im Textfeld anpassen, rechts unten übernehmen Sie anschließend Ihre Korrekturen. Zuletzt speichern Sie die Datei als PDF:
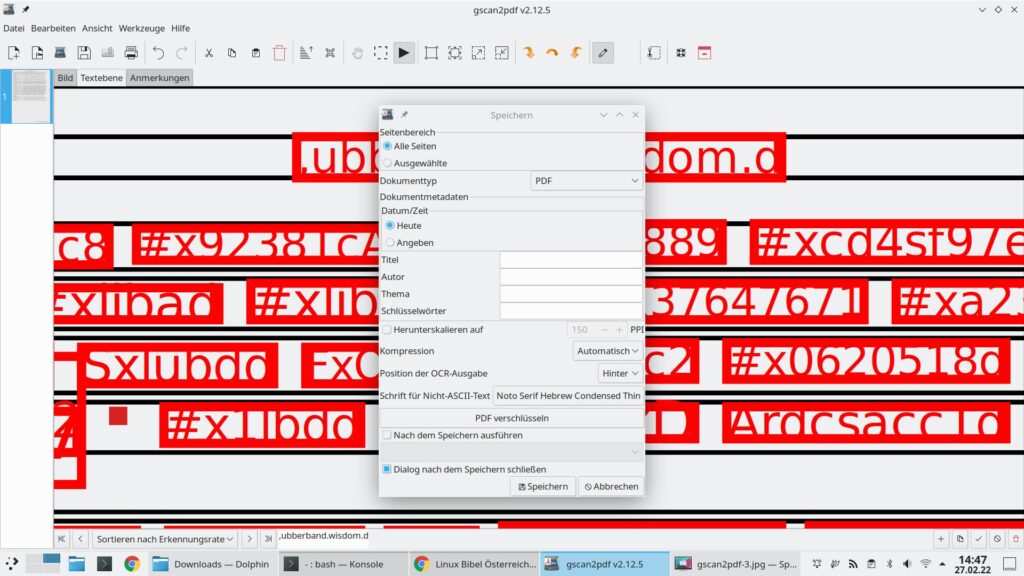
Die gespeicherte PDF-Datei lässt sich nun mit jeder Desktop-Suchmaschine durchsuchen.
 1
1

Noch keine Reaktion