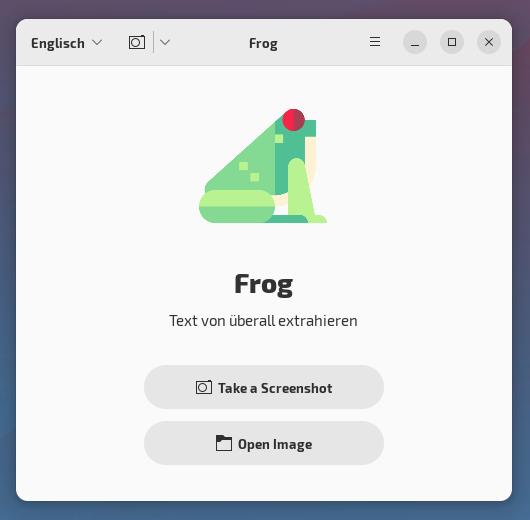
Beschreibung
Frog steht unter der MIT-Lizenz und liest komplexe Texte aus Fotos, Videos, Websites und QR-Codes aus. Es unterstützt die Aufnahme von Screenshots, kann aber auch Bilder direkt auslesen. Die Decodierung von QR-Codes wird ebenfalls unterstützt. Hierbei kommt die freie Tesseract-OCR Engine zum Einsatz.
Die zugehörigen Sprachmodule werden aus dem Tesseract-Repository heruntergeladen, der OCR-Prozess erfolgt lokal.
Installation
Frog gibt es als Flatpak und Snap-Paket. Das Flatpak installieren Sie mit folgenden Befehl:
flatpak install flathub com.github.tenderowl.frogNach der Installation empfiehlt sich das Herunterladen der gewünschten Sprachen.
Dies geschieht über das Dreipunkt-Menü: Preferences, Languages…
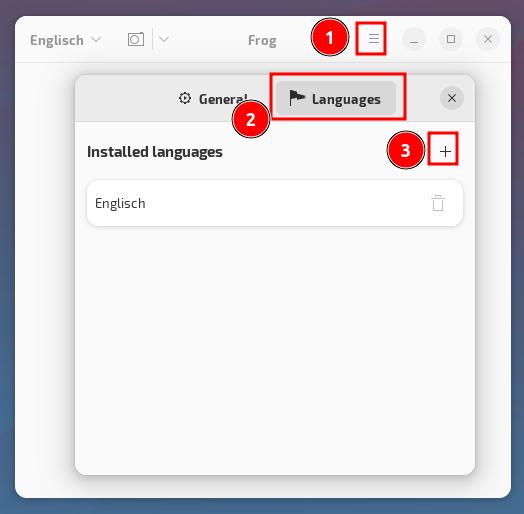
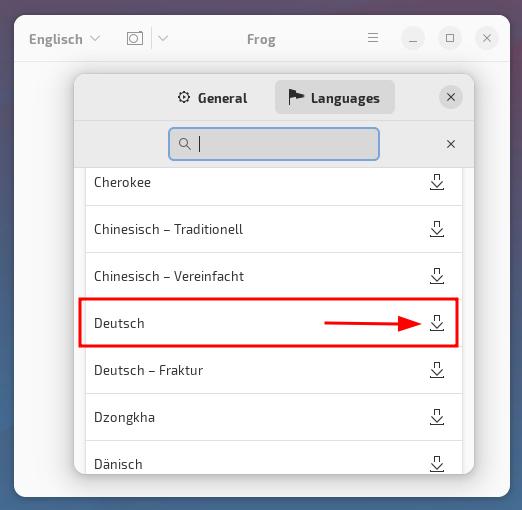
Es steht eine Vielzahl von Sprachen zur Verfügung – der Download dauert nur ein paar Augenblicke…
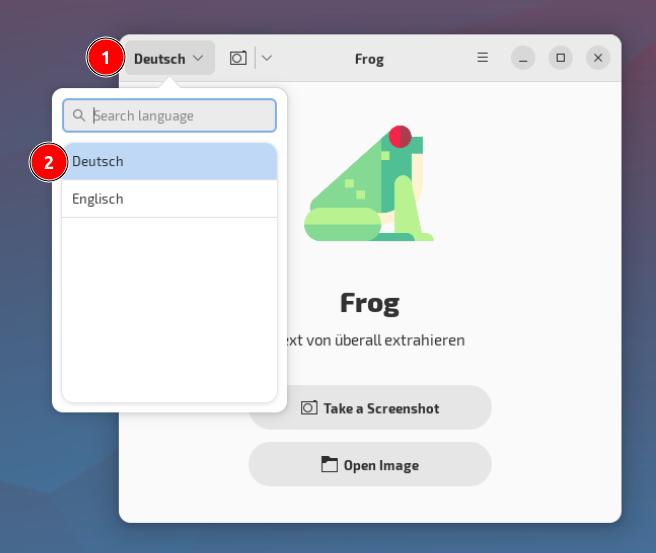
Anwendung
Nun öffnet man entweder ein bestehendes Bild, oder erstellt einen Screenshot eines Fotos, Videos, PDFs, usw.
Für den Screenshot wird das Standardwerkzeug der eigenen Desktop-Umgebung verwendet. Nach dem Erstellen des Screenshots erlaubt man mit einem Klick die
Weitergabe der Aufnahme an Frog.
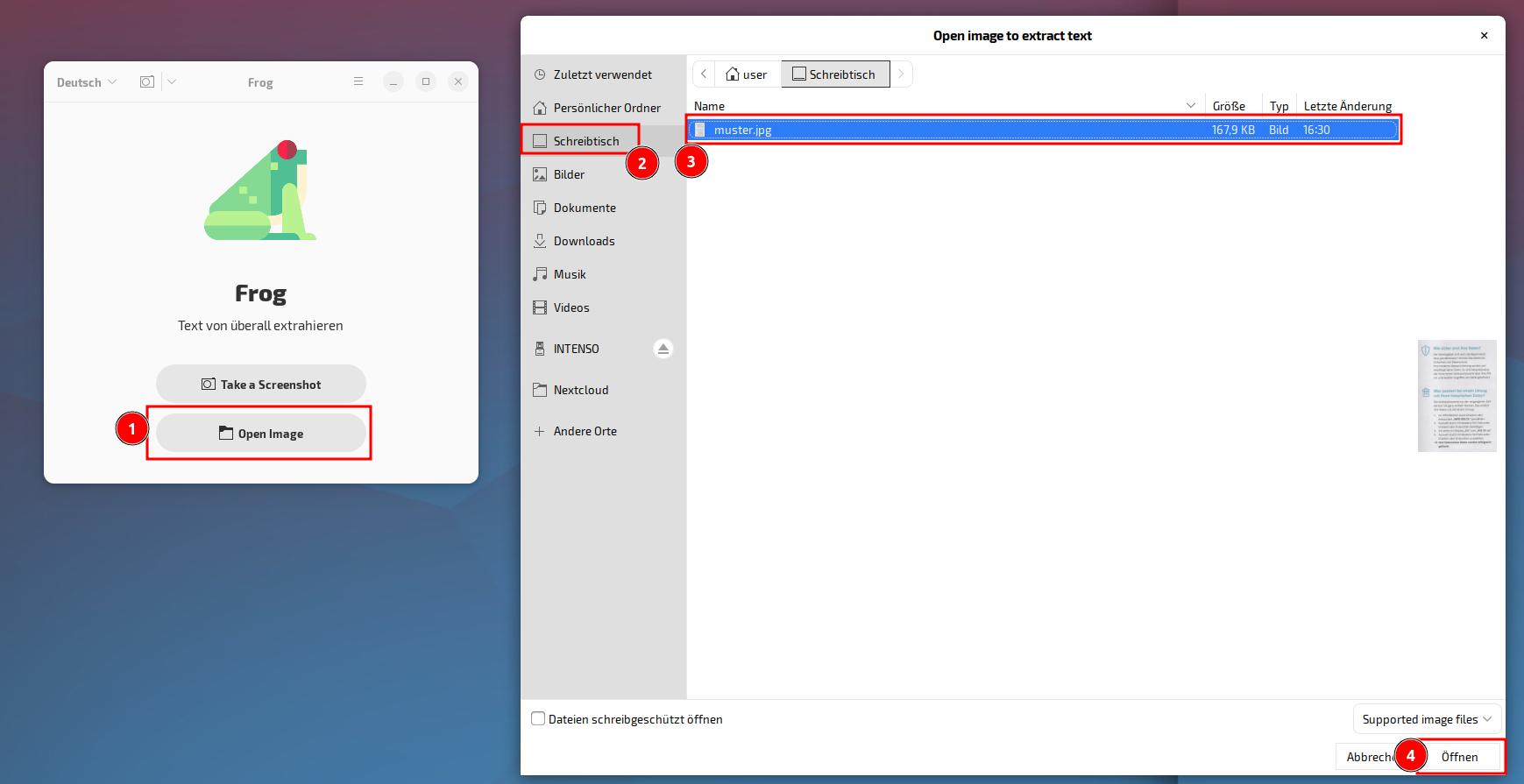
Folgendes Muster-Bild wurde ausgewählt…

Frog beginnt sofort mit der Text-Extraktion und stellt das Ergebnis in einem Textfenster dar…
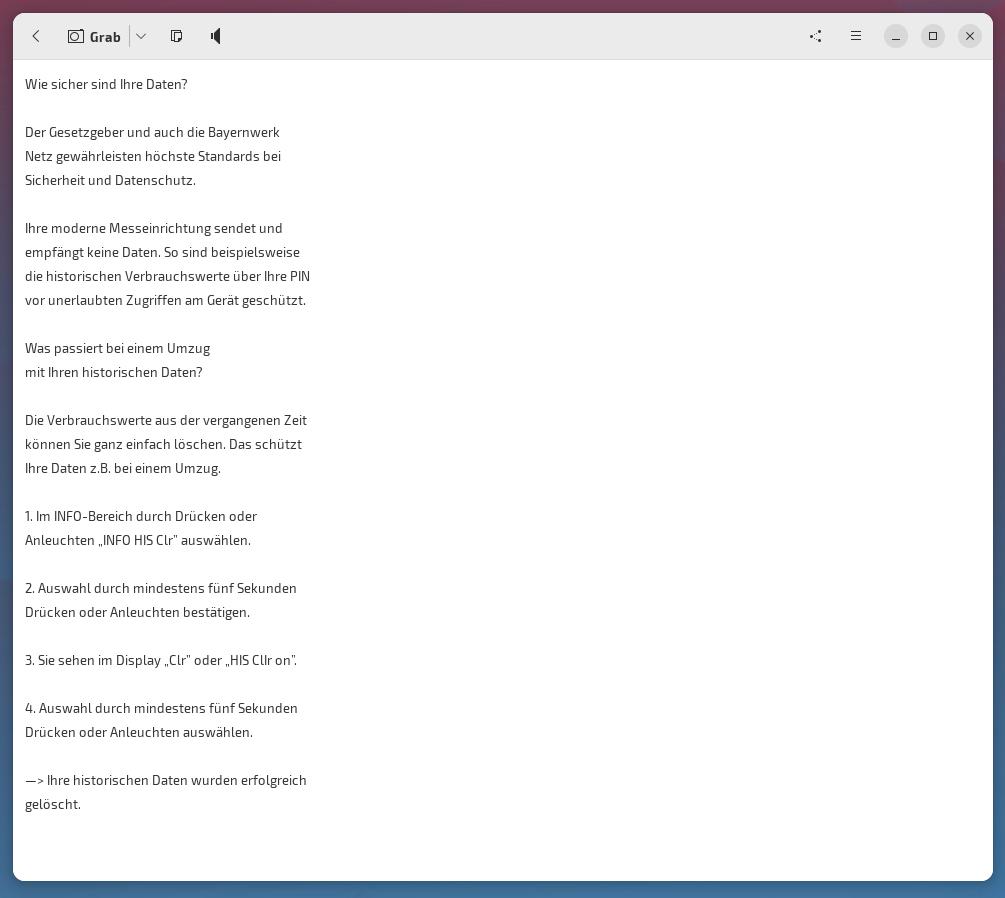
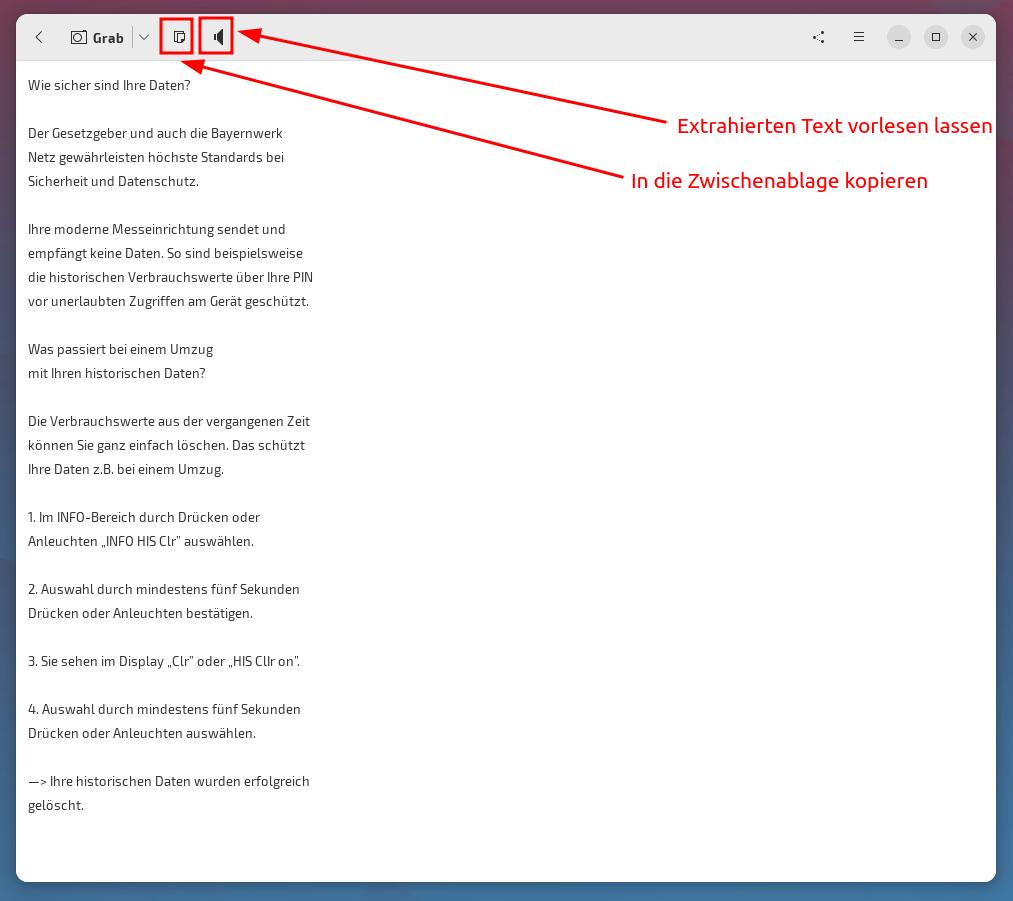
Der extrahierte Text kann nun sofort in die Zwischenablage kopiert und weiterverarbeitet werden – oder man lässt sich über das Lautsprecher-Symbol den Text vorlesen.
Anmerkung
Frog ist ein sehr nützliches Tool, um Texte aus Bildern auszulesen. Die Verwendung von Tesseract gestaltet sich hier unkompliziert und relativ fehlerfrei.
Positiv ist anzuführen, dass die Verarbeitung lokal stattfindet.
 3
3
 0
0
5 Reaktionen
GImageReader Texterkennung und Tesseract für OCR-OCRFeeder
Seit Windows 98 benutze ich Programme für OCR Texterkennung. Das Programm das ich benutzte war nicht unter Linux Nutzbar. Das erste Programm was ich für Linux fand war tesseract-ocr. Die Grafische Oberfläche gefiel mir nicht und der erkannte Text war schlecht. Ich musste den Text immer bearbeiten. Danach fand ich OCRFeeder. Der erkannte Text war etwas besser aber für mich nicht gut genug. Dann fand ich GimageReader. Dieses Programm kommt ziemlich dicht an das Programm das ich unter Windows benutzt hatte. Oben zwei Menüzeilen darunter drei Spalten zum Bearbeiten.
Tesseract-ocr muss für beide Programme Installiert werden. Dieses Paket ist wichtig für Sprachen.
apt install tesseract-ocr tesseract-ocr-deu
/home/administrator/GImageReader Texterkennung-Tesseract für OCR-OCRFeeder/gimagereader-Bildschirmfoto von 2023-10-12 21-02-01.png
Bild einfügen nicht möglich
Sowohl OCRFeeder als auch GImageReader verwenden Tesseract-OCR – ein Kommandozeilenprogramm ohne GUI – zur Texterkennung.
Beide Tools sind schon ziemlich in die Jahre gekommen – die Anwendung umständlich.
Mit Naps2 sowie Frog gelingen sehr gute Ergebnisse relativ unkompliziert. Normcap sei hier ebenfalls noch erwähnt.
Zu allen Tools gibt es hier Beiträge.
Vielen Dank für deine Info zebolon.
Ich benutze GimageReader hauptsächlich für Fotos von meinem Handy und, oder Screenshots vom Desktop wenn ich nicht Drucken kann. Dann möchte ich den Text. Dafür ist GimageReader ausreichend.
Für professionelle Ausgaben sind andere Programme besser geeignet.