Textshot ist mit NormCap verwandt, ist aber ein Terminal-Programm ohne GUI.
Seine Screenshot-Texte gehen wie bei NormCap in die Zwischenablage, zusätzlich sind sie im Terminal sichtbar.
Und Textshot kann sogar Screenshots in Intervallen (automatisch) produzieren, die dann im Terminal untereinander erscheinen. Benutzt man die Intervall-Funktion, ist ein Programm wie Clipit oder Diodon von Vorteil, sonst verliert man den Text der Zwischenablage bei jedem neuen Screenshot (wenigstens aber nicht den identischen Text im Terminal).
Leider hat man keinen bleibenden sichtbaren Auswahlrahmen, wie ihn NormCap hat.
In Erinnerung zu rufen ist hier, dass Screenshots natürlich von Texten in Bildern wie von „echten“ Texten gemacht werden können. Eigentlich selbstverständlich.
Mehr zum Programm Textshot hier: https://github.com/ianzhao05/textshot
Die Installation mit pip (die Installation von Tesseract mit den richtigen Sprachen ist Voraussetzung und ebenso, dass Tesseract von der Kommandozeile aus ansprechbar ist – mehr dazu dort, wo der Link hinführt):
pip install textshotDer Gebrauch auf der Kommandozeile:
textshot "deu+eng"Der Befehl mit Intervall-Option:
textshot --interval 200oder
textshot "deu+eng" --interval 200wobei Englisch Standardeinstellung ist und bei einem rein englischen Text „eng“ (mit Anführungszeichen) nicht gesetzt werden muss, „deu“ aber bei einem rein deutschen Text schon. Die Option 200 = 200 Millisekunden – 1000 = 1 Sekunde.
Man kann Textshot direkt starten, ohne das Terminal zu öffnen, wenn man eine Tastenkombi anlegt – unter Xfce so:
Einstellungen → Tastatur → Tastenkürzel für Anwendungen → Add usw. Unter Xfce kann man auch das Programmmenü öffnen und textshot schreiben und Enter drücken.
Ein Vergleich der Ergebnisse von NormCap (RAW bzw. PARSE) und Textshot, wenn ich den Text aus der Zwischenablage in LibreOffice Writer hineinkopiere:


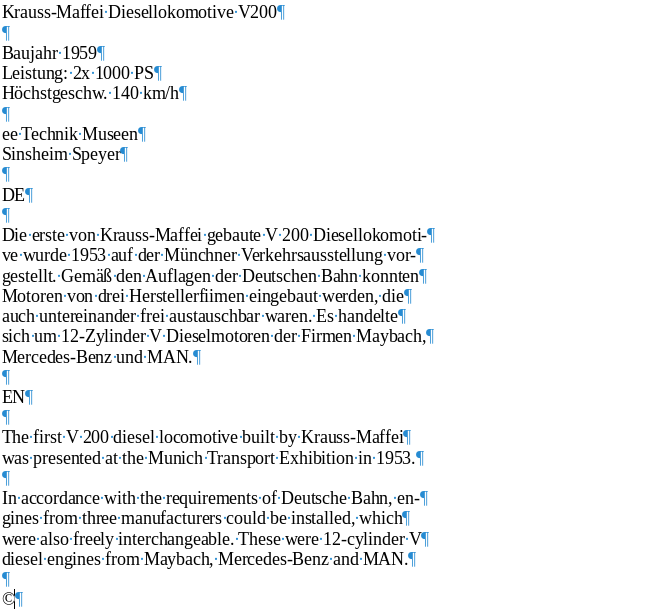
Textshot-Text in LibreOffice Writer enthält Absatz-Ende-Zeichen (sichtbar bei der Einstellung sichtbar) an jedem Zeilenende. Das ist unter Umständen sehr störend. Möchte man viele Texte so aus Bildern oder aus gescannten PDF-Seiten „herausholen“ und etwa in Writer weiterbearbeiten, kann es viel Arbeit bedeuten, die meisten dieser Absatz-Ende-Zeichen wieder zu entfernen. Ideal wäre es, die Einstellung Parse von NormCap mit der Intervall-Funktion von Textshot zu kombinieren. Andernfalls wäre für viele Seiten hintereinander – etwa ein Buch – das Programm OCRmyPDF (mit der sidecar-Option eine zusätzliche Textdatei erzeugend) eine gute Wahl, aber auch dieses Programm setzt solche Absatz-Ende-Zeichen.
Erstveröffentlichung: Mi 5. Apr 2023, 00:56
 2
2

Noch keine Reaktion