Beschreibung
gImageReader ist ein einfach zu bedienendes Frontend für das OCR-Programm Tesseract-OCR. Es bedient sich dazu des quelloffenen Tesseract, welches Texte (Buchstaben) in Bilddateien wie JPG, GIF, PNG oder auch aus PDF-Dateien analysiert und in editierbare Textdateien umwandelt.
Eine korrekte Rechtschreibung wird dabei bestmöglich berücksichtigt.
Die Software unterstützt mittlerweile zahlreiche Sprachen. Die Tool-Leiste bietet eine Vielzahl an Einstellungs- und Anpassungsmöglichkeiten.
Das Layout von Textblöcken wird automatisch erkannt. Einzelne Abschnitte können in Text umgewandet werden oder aber auch gleich das gesamte Dokument. Der Text lässt sich direkt in die Zwischenablage kopieren oder als TXT-, ODT- oder PDF-Datei exportieren.
Bei dunklen Scans bietet das Tool Optionen zur Bearbeitung von Helligkeit und Kontrast, damit die OCR-Erkennung präziser arbeiten kann.
Anwendung
Scans können direkt aus der Anwendung heraus durchgeführt werden.
Die Bedienung von gImageReader ist intuitiv – ein mühsames Abtippen von Texten entfällt.
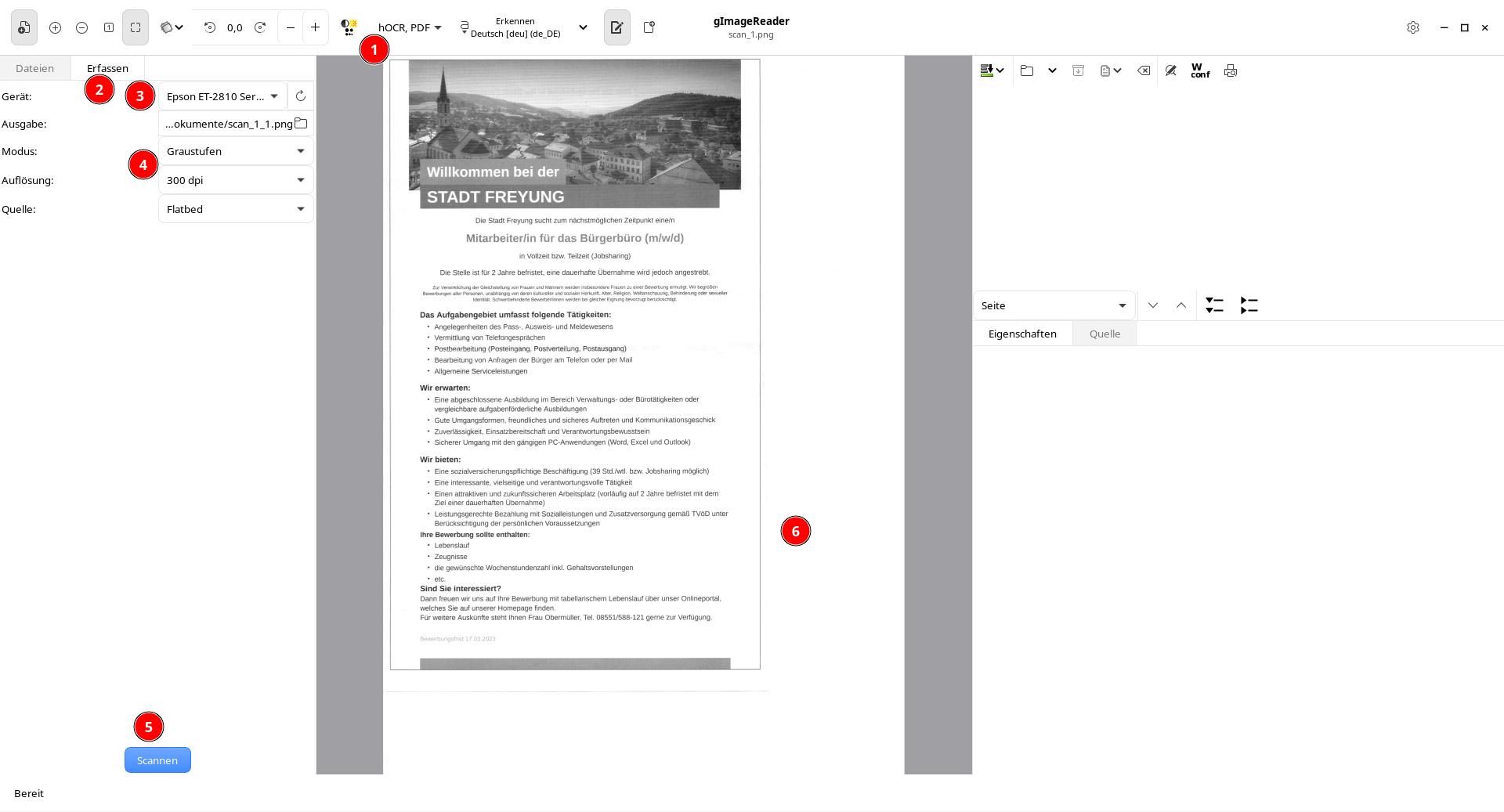
Die Anwendung öffnet zunächst ein leeres Fenster. Über die Schaltflächen Öffnen als auch Dateien lassen sich Bilddateien öffnen, die in der Seitenleiste als Vorschaubilder aufgelistet werden. Das jeweilige Bild wird in der Mitte dargestellt, die Ansicht lässt sich über die Schaltflächen oben einstellen (Zoomen, Einpassen, Drehen) – erreichbar über den Reiter Ansicht. Über die Schaltfläche Bildbearbeitungsregler anzeigen lassen sich Einstellungsmöglichkeiten zur Helligkeit, Kontrast und Auflösung des Bildes einblenden, sehr sinnvoll für schlechte Vorlagen etc.
Im Beispiel importieren wir ein Bild über die Scanner-Schnittstelle. Befolgen Sie dazu die nummerierten Schritte wie vor beschrieben.
Eine Vorschau erfolgt im mittleren Bereich des Anwendungsfensters.
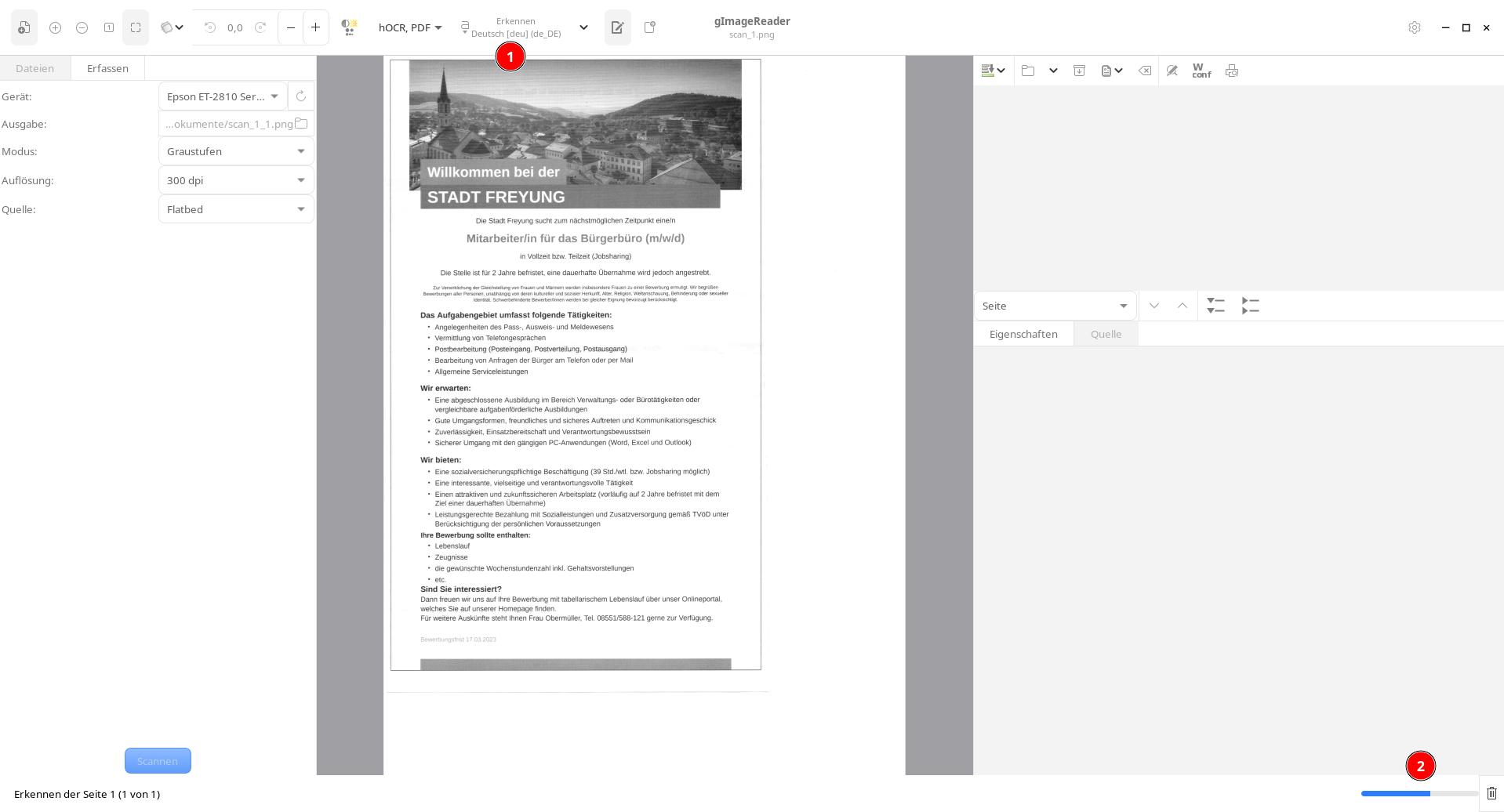
Im Bild selbst kann über Ziehen bei gedrückter linke Maustaste-Taste ein Ausschnitt festgelegt werden, der ausgelesen werden soll, was gerade bei verschachtelten Vorlagen mit Bildern nützlich sein kann. Die Erkennung wird dann über die Schaltfläche Erkennen (bei Teilauswahl Selektion erkennen) gestartet. Das Ergebnis erscheint nach kurzer Zeit im Fenster daneben.
„Fehlerhaft“ erkannte Wörter sind rot unterstrichen, in dem Fenster kann direkt korrigiert und umgestellt werden. Per Kontextmenü eröffnen sich weitere Bearbeitungsoptionen. Mit rechten Maustaste-Klick auf ein unterschlängeltes Wort werden Alternativen angeboten, die direkt angewandt werden, oder auch das Wort in das Benutzerwörterbuch aufnehmen. Weitere Erkennungen können angehängt, oder in den Text an die Stelle des Cursors eingefügt werden. Über die Schaltfläche Suchen und ersetzen lassen sich häufig auftretende Fehler einfach korrigieren.
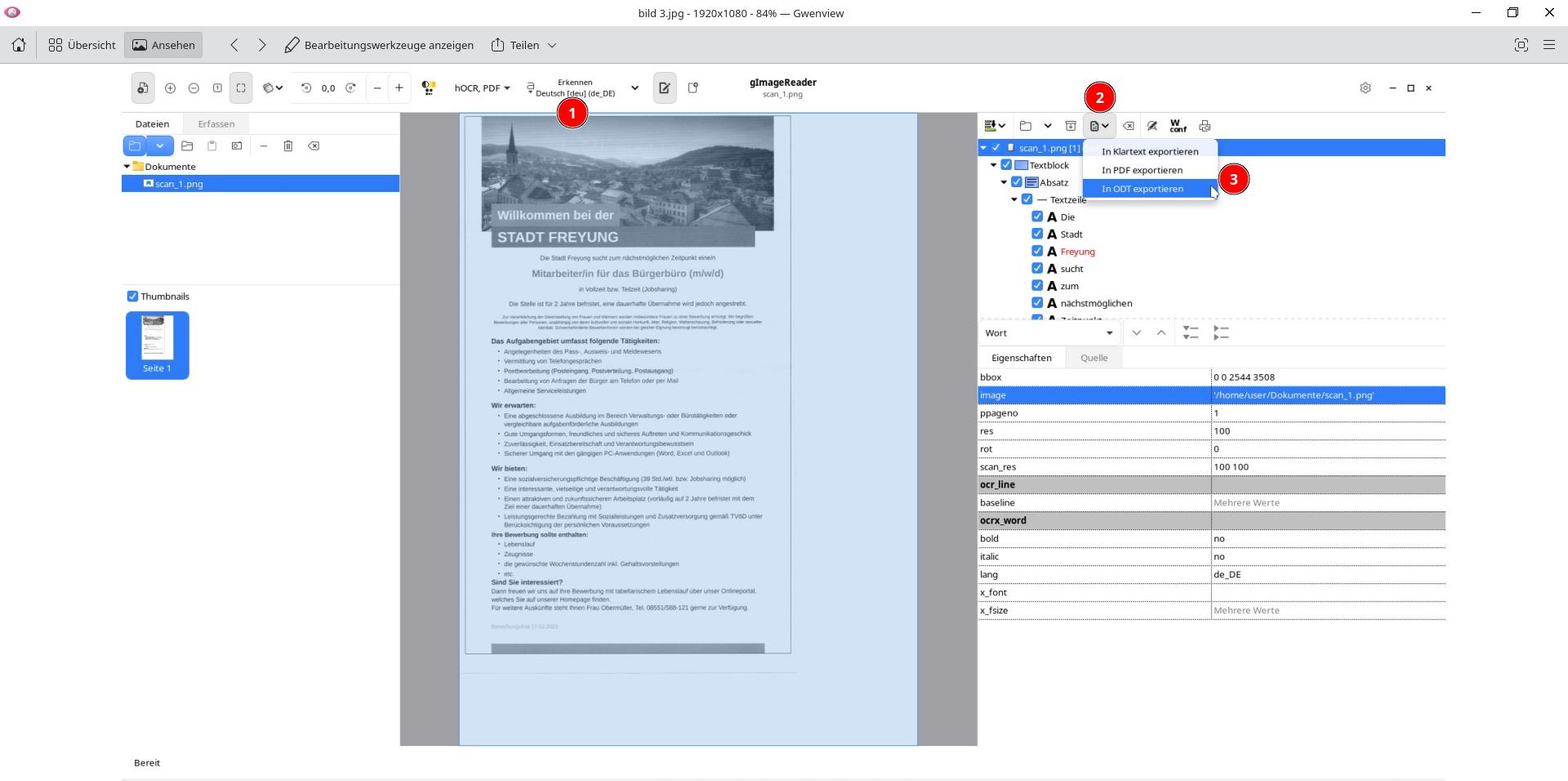
Ist man mit dem Ergebnis weitgehend zufrieden, erfolgt zur Weiterverarbeitung der Export als TXT-, ODT- oder auch PDF-Datei.
Die Schaltfläche dazu finden Sie im Bild oben unter (2) und dann zur Formatauswahl (3).
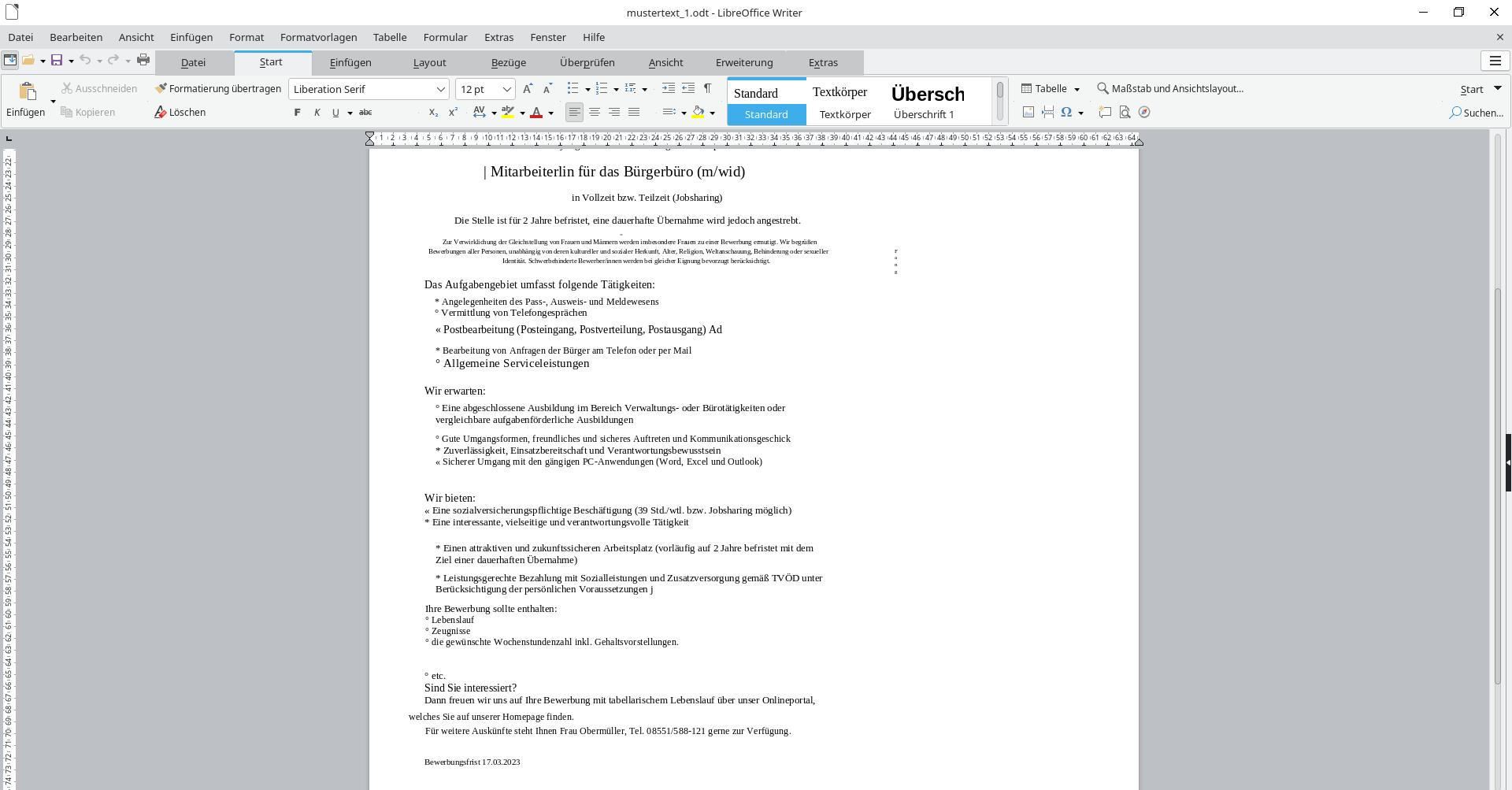
Hier im Beispiel wurde zur Weiterverarbeitung das *.odt-Format gewählt, mit dem die Ausgabe in Libre Office Writer noch komfortabler korrigiert und neu formatiert werden kann.
Installation
Zur Texterkennung benötigt gImageReader Tesseract-OCR.
Unter Ubuntu, Debian und Linux Mint befindet sich alles im jeweiligen Repository. Die Installation erfolgt im Terminal wie folgt:
sudo apt install tesseract-ocr tesseract-ocr-deuNun noch das gImageReader-Frontend:
sudo apt install gimagereaderDie Anwendung finden Sie nun unter Menü -> Grafik – alternativ auch per Tastenkombination [Alt + F2] mit der Eingabe von:
gimagereaderAnmerkung
Für eine optimale spätere Texterkennung ist in der Regel eine Auflösung von 300 dpi sowie der Graustufen-Modus ausreichend.
Erstveröffentlichung von @zebolon » Sa 1. Apr 2023, 10:28
 1
1
 1
1
Noch keine Reaktion